Intro to HTML & Web Scraping
Web Scraping Toolkit
requests
Make HTTP GET/POST requests to fetch HTML pages.
BeautifulSoup
Parse HTML and extract data via tag, class, or CSS selectors.
Selenium / Playwright
For sites that require JavaScript execution before scraping.
Respect robots.txt
Always check terms of service and rate limits before scraping.
Noble Desktop's Python Programming Immersive covers AI APIs, data analysis, and modern Python development.
Get started with web scraping in this Python web scraping tutorial. Learn the fundamentals of HTML that you'll need to understand a site structure and effectively scrape data from the site.

One of the largest and most ubiquitous sources of data is all around us. It is the web. If there’s anything I want you to remember after reading this tutorial, it is this: “If you can see it on a website, it can be scraped, mined, and put into a dataframe.” However, before we begin talking about web scraping, it is important to cover how webpages are constructed as unstructured data in HyperText Markup Language (HTML). In this article, we will familiarize ourselves in reading and navigating HTML. Afterwards, we will use Beautiful Soup and Requests to scrape a website called Datatau. In part II of the Web Scraping series, we will cover a technique called XPath and look at a web scraping workflow using a framework called Scrapy.
In HTML document object model (DOM), everything is considered a node:
- The document is a document node.
- HTML elements are element nodes.
- All HTML attributes are attribute nodes.
- Text inside HTML elements are text nodes.
- This is what people usually target in web scraping projects. The actual text nugget after digging through all the hierarchy of nodes.
HTML Hierarchy
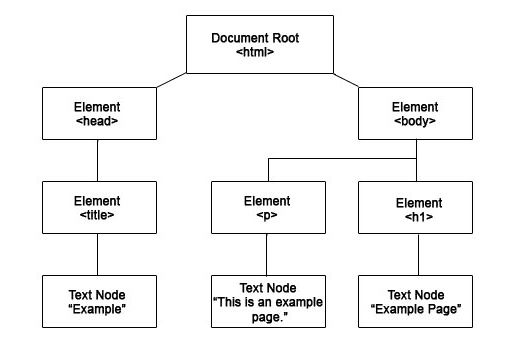
If you visualize the node above, it looks like this. The document node is the root and there will be multiple elements that each contain smaller elements like title, paragraph, and h1. Each of these smaller elements will contain text nodes that people usually mine. Let’s transform the nodes into actual code so we can familiarize ourselves with HTML.
Data Import and URL Request

It’s important to check response.status_code. Some websites will block your requests. Make sure you get a “200”.
Scraping Code

Looks good! We just scraped the title, link, and origin URL. Let’s put all of this in a Pandas dataframe next.
List to Pandas Dataframe
Once we have a list of dictionaries, we can simply import Pandas and use the DataFrame method to convert it into a dataframe.
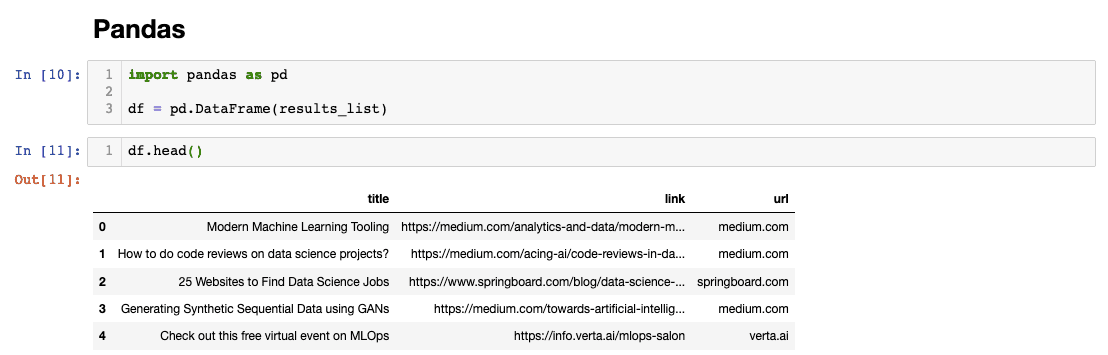
Great job if you were able to follow along and scrape the website! I think the scraping code went from 0-60 real quick so don’t beat yourself up if you get stuck. There’s a lot of great resources out there and our Python course can definitely get you up to speed. Stick around for Part II of the web scraping series where we’ll learn about Xpath.