Machine Learning Overview & Tutorial
What This Tutorial Covers
Supervised Learning
Predict labels from training examples.
Unsupervised Learning
Find structure in unlabeled data.
scikit-learn
Python's go-to ML library for classical models.
Noble Desktop's Data Science & AI Certificate teaches Python in depth — from data analysis through machine learning.
Learn what machine learning is, the various types of machine learning models, and walk through building a machine learning model in Python with this step-by-step guide.

ML Tutorial 101 (Iris Dataset)
Nine out of ten data scientists encountered this dataset from the University of Irvine when they first started out on their data science journey and created different classification algorithms from it. This dataset recorded different features from iris flowers and we’ll be creating three models to classify which irises belong to which species. Let’s join the party, it’s time to code!
1. Import Libraries
We’ll be using a lot of packages from scikit-learn to split and cross-validate our data, import classification models, and measure the accuracy of our predictions.
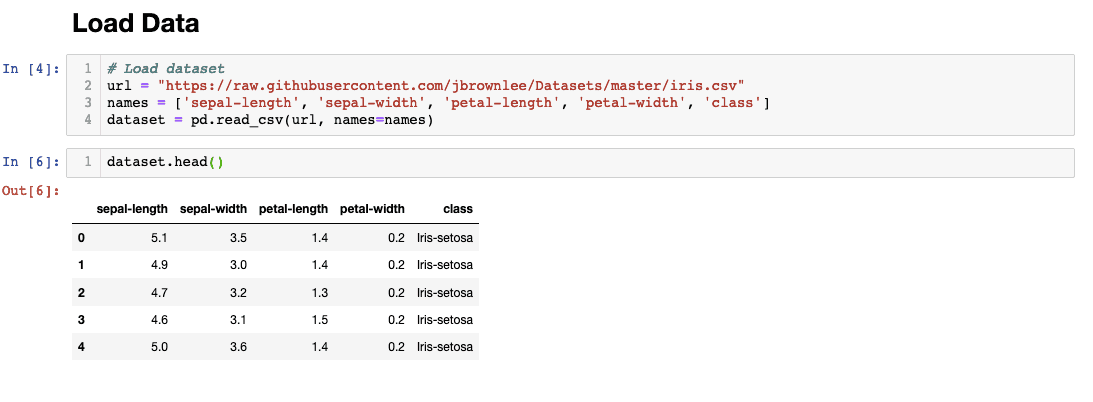
2. Download the Data
We’ll be using a link to download the data from GitHub and assign column names manually.
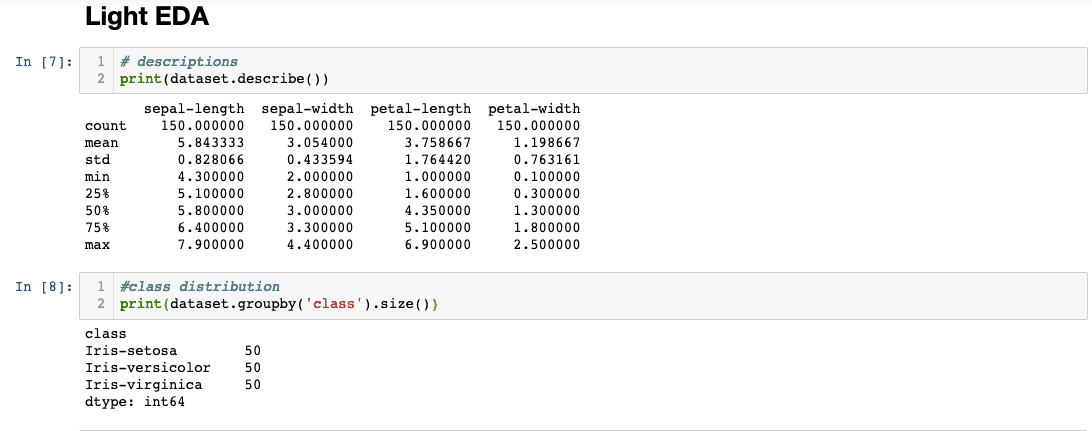
3. Light EDA
It is important to see the class distribution of your dataset because unbalanced classes can adversely affect your models. Training your models on unbalanced classes can make your models not accurate or too sensitive to one type of class, resulting in a lot of false positives. Feel free to visualize your data using dataset.hist() or dataset.plot(kind = 'box') to see distributions and feature frequencies.
4. Train/Test Split + Training the Models
I’ve created training and validation splits in my data. 80% of the data is used for training and 20% for validating results. Afterward, I’ve trained three models to classify different types of irises:
- Logistic Regression
- KNeighbor Classifier
- Decision Tree Classifier

On line 10, you can see I’ve decided to use accuracy as the determining score for model performance. Different types of model performance metrics could be used depending on the type of question you’re trying to solve but accuracy seemed apt for this exercise.
Finally, on line 13, you can see I’ve printed out the mean of cross-validated model scores and the standard deviation. Since the decision tree classifier performed the best, I’ll use that to demonstrate predicting it against the validation data we’ve been holding out.
5. Validation
I’ve created a variable named ‘model’ and assigned Decision Tree Classifier as the value. I’ve trained it on line two and predicted it against the test/validation dataset I’ve been withholding.
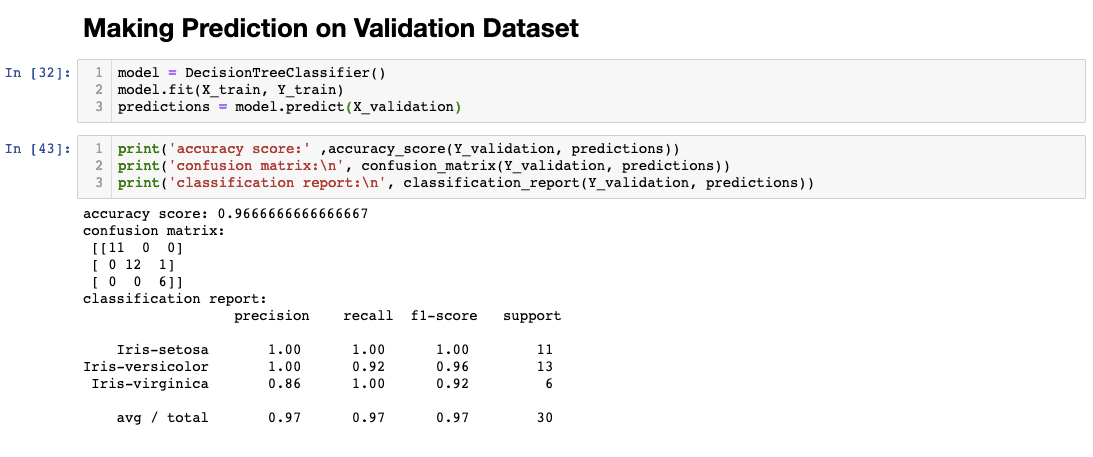
You can see that it reached a 96% accuracy rate. I’ve also included a confusion matrix and classification report for completeness. I won’t describe how to read it in this article because it is outside the scope, but you can read more about it here.
Congrats on completing your first data science project!